Collect Twitter Data with Python and store in MongoDB

Hi All,
For my first project I have decided to collect a couple days the hashtags “#datascience” and “#datascientist” from twitters timeline with python and store into a MongoDB for later use. First of all we need to install MongoDB, Python and the necessary libraries for streaming Twitter and storing into MongoDB with Python. You need a sudo non-root user, which you can set up by following steps. Let’s start!!
Installing MongoDB
I have MongoDB installed as described on the MongoDB site you can find it here. Why should I write it again :). I installed it on linux CentOS 7, and used the Red Hat installation guide.
You can check if MongoDB is running and listen on the tcp port.
|
1 2 3 4 |
$ ps aux | grep -i mongo mongod 1138 0.5 8.3 1502560 243764 ? Sl Jul04 88:26 /usr/bin/mongod -f /etc/mongod.conf $ sudo netstat -atnp | grep -i mongo tcp 0 0 0.0.0.0:27017 0.0.0.0:* LISTEN 1138/mongod |
Installing Python
Python is already installed during the installation of CentOS, but I want to install Anaconda Python. Anaconda is a completely free enterprise-ready Python distribution for large-scale data processing, predictive analytics, and scientific computing. You can find it here.
|
1 2 |
wget https://3230d63b5fc54e62148e-c95ac804525aac4b6dba79b00b39d1d3.ssl.cf1.rackcdn.com/Anaconda-2.2.0-Linux-x86_64.sh sudo bash Anaconda-2.2.0-Linux-x86_64.sh |
After installation you can test if you are using Anaconda Python. If not you should check your path settings and correct that.
|
1 2 3 4 5 6 7 |
$ python Python 2.7.9 |Anaconda 2.2.0 (64-bit)| (default, Mar 9 2015, 16:20:48) [GCC 4.4.7 20120313 (Red Hat 4.4.7-1)] on linux2 Type "help", "copyright", "credits" or "license" for more information. Anaconda is brought to you by Continuum Analytics. Please check out: http://continuum.io/thanks and https://binstar.org >>> |
Installing necessary libraries for streaming Twitter and storing into MongoDB
If your path is correct you have also pip available, we need this for installing the library tweepy and pymongo. Tweepy is an easy-to-use Python library for accessing the Twitter API. PyMongo is a Python distribution containing tools for working with MongoDB, and is the recommended way to work with MongoDB from Python
|
1 2 |
$ sudo pip install tweepy $ sudo pip install pymongo |
Create a Twitter Application
First we need to create a Twitter Application, I will explain how to create a Twitter application and get your API access keys and tokens. These keys and tokens we need to authenticate the Python client application with Twitter.
Visit https://apps.twitter.com/ then log in using your Twitter account credentials. Once logged in, click the button labeled Create New App.
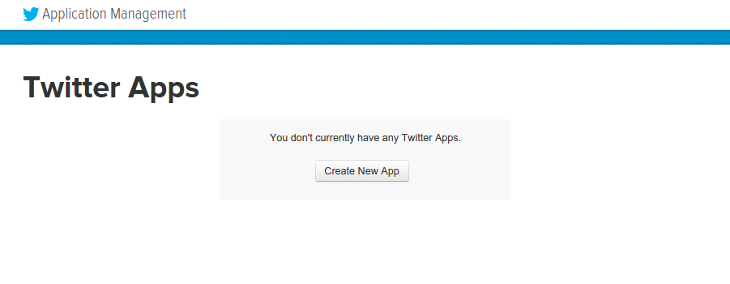
You will be redirected to the application creation page. Fill out the required form information and accept the Developer Agreement at the bottom of the page, then click the button labeled Create your Twitter application.
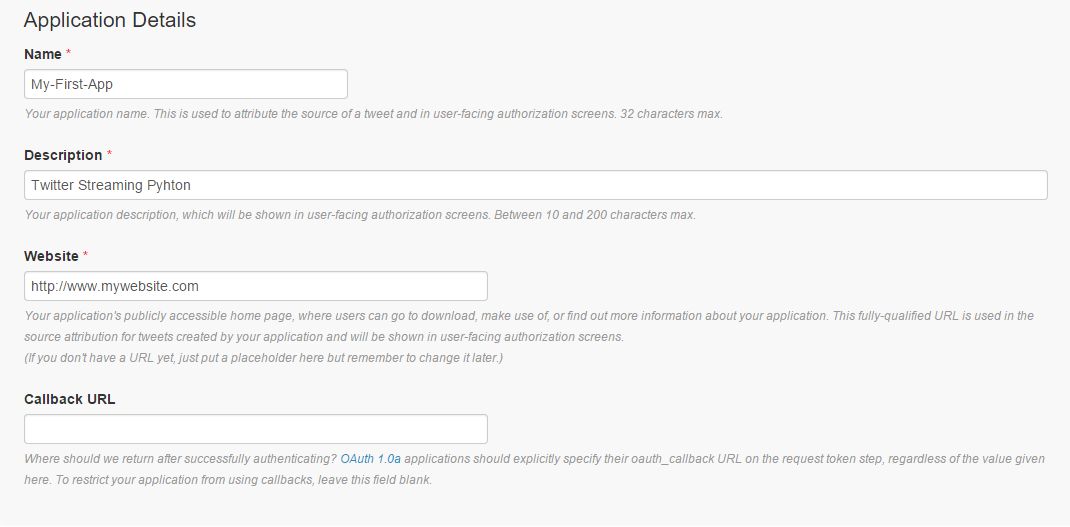
Don’t forget to click the checkbox that says Yes, I agree underneath the Developer Agreement.
Now you have setup your Twitter Application and you’re ready to write your stream listener script in Python and get your tweets and save it into MongoDB.
Creating the script
Create a file twitter_stream_to_mongodb.py and start with importing the libraries
|
1 2 3 4 |
# Import libraries import json import pymongo import tweepy |
After that we are setting up our twitter application variables that will be used in the stream listener. These are necessary for the OAuth Authentication.
|
1 2 3 4 5 |
# Setting the variables and will be used in the stream listener. consumer_key = "your consumer key" consumer_secret = "your consumer secret key" access_key = "your access token" access_secret = "your access token secret" |
The next step is creating an OAuthHandler instance. Into this we pass our consumer token and secret which was given to us in the previous paragraph.
|
1 2 3 4 5 6 |
# creating an OAuthHandler instance. Into this we pass our consumer token and secret. auth = tweepy.OAuthHandler(consumer_key, consumer_secret) # Set access token auth.set_access_token(access_key, access_secret) # Construct the API instance api = tweepy.API(auth) |
Tweepy provides a class to access the Twitter Streaming API: StreamListener. We just need to create our own class StreamListener that inherits from tweepy.StreamListener and override some functions to adapt its behavior to output the data into MongoDB.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
class CustomStreamListener(tweepy.StreamListener): """ tweepy.StreamListener is a class provided by tweepy used to access the Twitter Streaming API. It allows us to retrieve tweets in real time. """ def __init__(self, api): self.api = api super(tweepy.StreamListener, self).__init__() # Connecting to MongoDB and use the database twitter. self.db = pymongo.MongoClient().twitter def on_data(self, tweet): ''' This will be called each time we receive stream data and store the tweets into the datascience collection. ''' self.db.datascience.insert(json.loads(tweet)) def on_error(self, status_code): # This is called when an error occurs print >> sys.stderr, 'Encountered error with status code:', status_code return True # Don't kill the stream def on_timeout(self): # This is called if there is a timeout print >> sys.stderr, 'Timeout.....' return True # Don't kill the stream |
After the class is created we can create the stream object and start the listener.
|
1 2 3 4 5 6 7 8 |
# Create our stream object sapi = tweepy.streaming.Stream(auth, CustomStreamListener(api)) ''' The track parameter is an array of search terms to stream. In this example I will use filter to stream all tweets containing the hashtags datascience and datascientist. ''' sapi.filter(track=['#datascience', '#datascientist']) |
Now the script is ready we can start it and let it run for a while.
|
1 |
python twitter_stream_to_mongodb.py & |
There is no need to create the twitter database and the datascience collection, if they don’t exist, PyMongo will create them for you. After a short time we have streamed some tweets. Let’s look into the MongoDB console to explore some tweets.
Look into MongoDB
Start the MongoDB console and use direct our database twitter
|
1 2 3 4 |
$ mongo twitter MongoDB shell version: 3.0.4 connecting to: twitter > |
Check is the collection datascience exists and count the number of tweets we have gathered
|
1 2 3 4 5 6 |
> show collections datascience system.indexes > db.datascience.count() 6859 > |
Let’s look at a tweet.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 |
> db.datascience.findOne({}) { "_id" : ObjectId("5598e3fafa32e52ffa8cb740"), "contributors" : null, "truncated" : false, "text" : "https://t.co/Dtcl5pbsg3 Golang data structures #datascience #bigdata #machinelearning #hadoop #ec2 #google", "in_reply_to_status_id" : null, "id" : NumberLong("617603798534647808"), "favorite_count" : 0, "source" : "<a href="http://lazyprogrammer.me" rel="nofollow">Lazy Programmer Poster</a>", "retweeted" : false, "coordinates" : null, "timestamp_ms" : "1436083194751", "entities" : { "user_mentions" : [ ], "symbols" : [ ], "trends" : [ ], "hashtags" : [ { "indices" : [ 47, 59 ], "text" : "datascience" }, { "indices" : [ 60, 68 ], "text" : "bigdata" }, { "indices" : [ 69, 85 ], "text" : "machinelearning" }, { "indices" : [ 86, 93 ], "text" : "hadoop" }, { "indices" : [ 94, 98 ], "text" : "ec2" }, { "indices" : [ 99, 106 ], "text" : "google" } ], "urls" : [ { "url" : "https://t.co/Dtcl5pbsg3", "indices" : [ 0, 23 ], "expanded_url" : "https://github.com/Workiva/go-datastructures", "display_url" : "github.com/Workiva/go-dat…" } ] }, "in_reply_to_screen_name" : null, "id_str" : "617603798534647808", "retweet_count" : 0, "in_reply_to_user_id" : null, "favorited" : false, "user" : { "follow_request_sent" : null, "profile_use_background_image" : true, "default_profile_image" : false, "id" : 403054479, "verified" : false, "profile_image_url_https" : "https://pbs.twimg.com/profile_images/492723325706051586/Fx_QDmN6_normal.jpeg", "profile_sidebar_fill_color" : "DDEEF6", "profile_text_color" : "333333", "followers_count" : 80, "profile_sidebar_border_color" : "FFFFFF", "id_str" : "403054479", "profile_background_color" : "131516", "listed_count" : 16, "profile_background_image_url_https" : "https://pbs.twimg.com/profile_background_images/492727362123886592/eLwJ4qKy.jpeg", "utc_offset" : -14400, "statuses_count" : 172, "description" : "#BigData #Engineer and #DataScientist. #Consultant #Freelancer and #Tutor. I lead #tech at a few early-stage #startups. I like to #Zen out.", "friends_count" : 214, "location" : "New York, NY", "profile_link_color" : "009999", "profile_image_url" : "http://pbs.twimg.com/profile_images/492723325706051586/Fx_QDmN6_normal.jpeg", "following" : null, "geo_enabled" : false, "profile_banner_url" : "https://pbs.twimg.com/profile_banners/403054479/1406310187", "profile_background_image_url" : "http://pbs.twimg.com/profile_background_images/492727362123886592/eLwJ4qKy.jpeg", "name" : "Kenzo Kai", "lang" : "en", "profile_background_tile" : false, "favourites_count" : 0, "screen_name" : "lazy_scientist", "notifications" : null, "url" : "http://lazyprogrammer.me", "created_at" : "Tue Nov 01 23:27:51 +0000 2011", "contributors_enabled" : false, "time_zone" : "Eastern Time (US & Canada)", "protected" : false, "default_profile" : false, "is_translator" : false }, "geo" : null, "in_reply_to_user_id_str" : null, "possibly_sensitive" : false, "lang" : "tl", "created_at" : "Sun Jul 05 07:59:54 +0000 2015", "filter_level" : "low", "in_reply_to_status_id_str" : null, "place" : null } > |
That looks nice, now we can do some analysis with this data, that will be another project.
You can find the python code on my GitHub, if you have questions follow me on Twitter.

I’m creative, imaginative, free-thinking, daydreamer and strategic who needs freedom, peace and space to brainstorm and to fantasize about new and surprising solutions. Generates ideas and solves difficult problems, sees all options, judges accurately and wants to get to the bottom of things.
Interested in Data Science, Data Analytics, Running, Crossfit, Obstacle Running and Coffee.